
Microsoft has transitioned to a DCR-based log ingestion and manual schema management for tables. Many organizations are adopting this modern approach to parse, filter, and enrich logs during ingestion. While effective, this system can incur unnecessary expenses if not used properly, leading to billable fields that remain inaccessible when querying events. We refer to these as “phantom fields.”
The Shift in Schema Management
Previously, with the automatic schema management setup, when a new field was added to a new event the table schema would automatically reflect that change by including the new field.
With the new manual schema management, if you add a new field to your events but do not manually add that field to the table schema, then the data will remain inaccessible. Despite the inability to query that field, you will still incur charges for the data stored in it.
The next diagram shows how the billable data increases as more and more phantom fields are continuously added to the ingested logs, while the accessible data (free and billable) remains the same:

At BlueVoyant, we’ve observed new clients and their former MSSPs overlooking this issue, leading to unnecessary expenses in Sentinel. Without proper tuning, DCRs can result in significant costs. In some cases, phantom fields accounted for 65% of the entire table. Addressing these issues can significantly lower ingestion costs.
Common Scenarios
Rather than presenting general cases, I have chosen to highlight very specific scenarios. This approach aims to help you in easily identifying similar behaviors within your own environment. Ultimately, the core problem is that an event contains a field that is not represented in the table schema.
1. Log Splitting
Log Splitting refers to the process of directing logs from a single input to multiple outputs, typically based on some criteria. For instance, log splitting can be used to capture various log types via Syslog and route them into their respective custom tables. This allows for the forwarding of firewall logs to the Firewall_CL table, Access Point logs to the AP_CL table, and all other events to the default Syslog table.
In such a configuration, there is one input schema and multiple, potentially distinct, output table schemas.
For instance, suppose you have firewall logs picked up via Syslog, and you intend to forward these logs to the Firewall_CL custom table using log splitting. The schema of the Firewall_CL table is simple, consisting of:
- TimeGenerated:datetime (mandatory)
- Message:string (to hold all Syslog data)
In setups like this with custom tables, it is typical to retain very few fields, with the essential data being transferred from the SyslogMessage field to the Message field. While common practice for lots of log sources, it is neither mandatory nor strictly necessary.
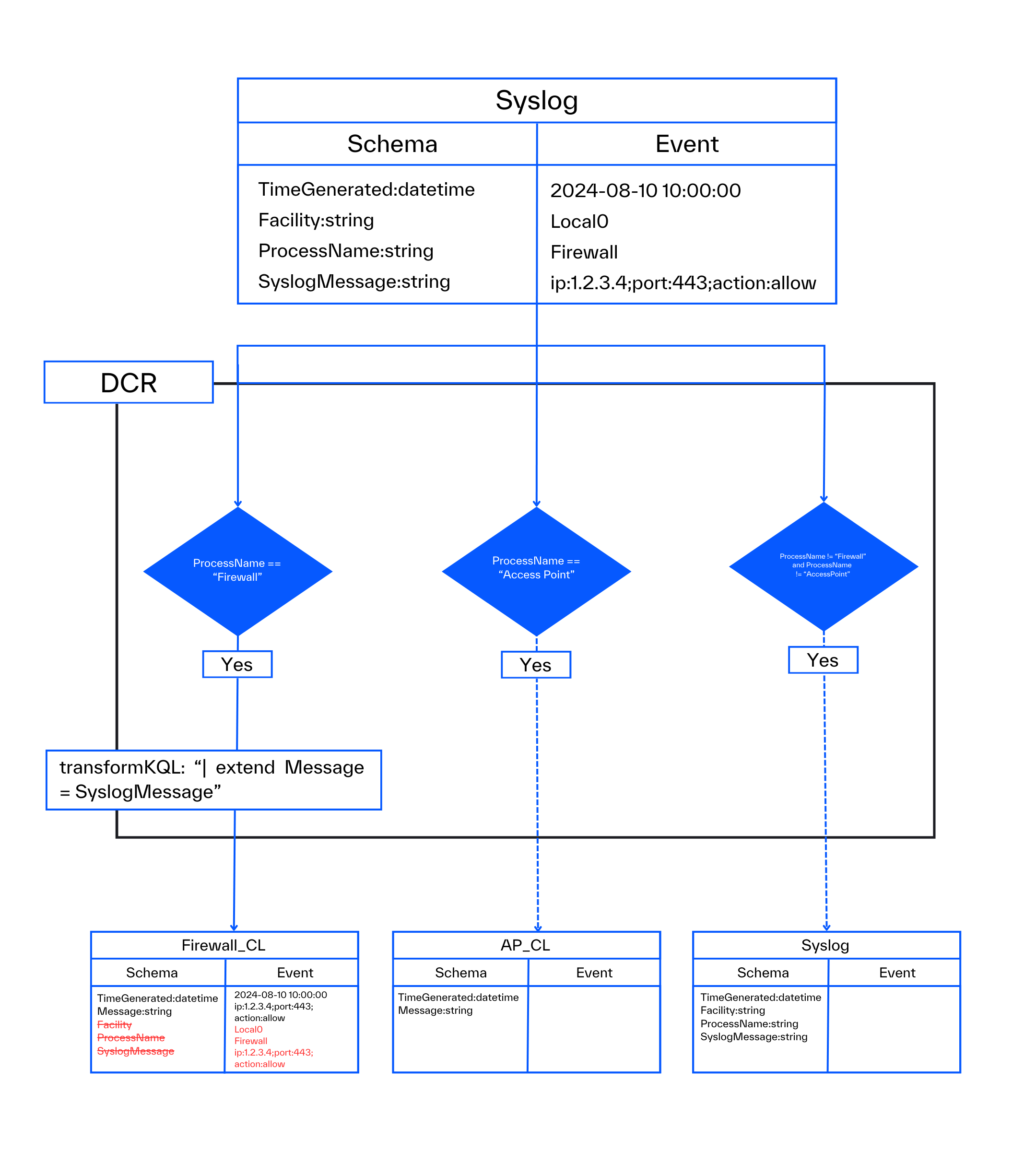
The incoming stream will consist of Syslog data with its default schema, while the target table will be the Firewall_CL table. You can imagine an ingestion-time transformation like this to filter and process the data:
source | where ProcessName == “Firewall” | extend Message = SyslogMessage
You can identify two issues with this transformation:
- Due to the usage of ‘extend’ (instead of project-rename) you created a new Message field, while you kept the SyslogMessage field, which is not part of the destination schema
- The Syslog table schema contains a lot of additional fields, like the Facility or Severity fields. All of these are going to end up as phantom fields, since they are not part of the destination schema, but they are part of the input schema (Syslog)
To eliminate such issues, you must get the input schema, run it through the ingestion-time transformation and then compare this output with the schema of the destination table. If the output contains fields not part of the destination table schema, then you will end up with phantom fields. Inaccessible, but billable fields.
2. Schema Modification of DCR-based Custom Tables
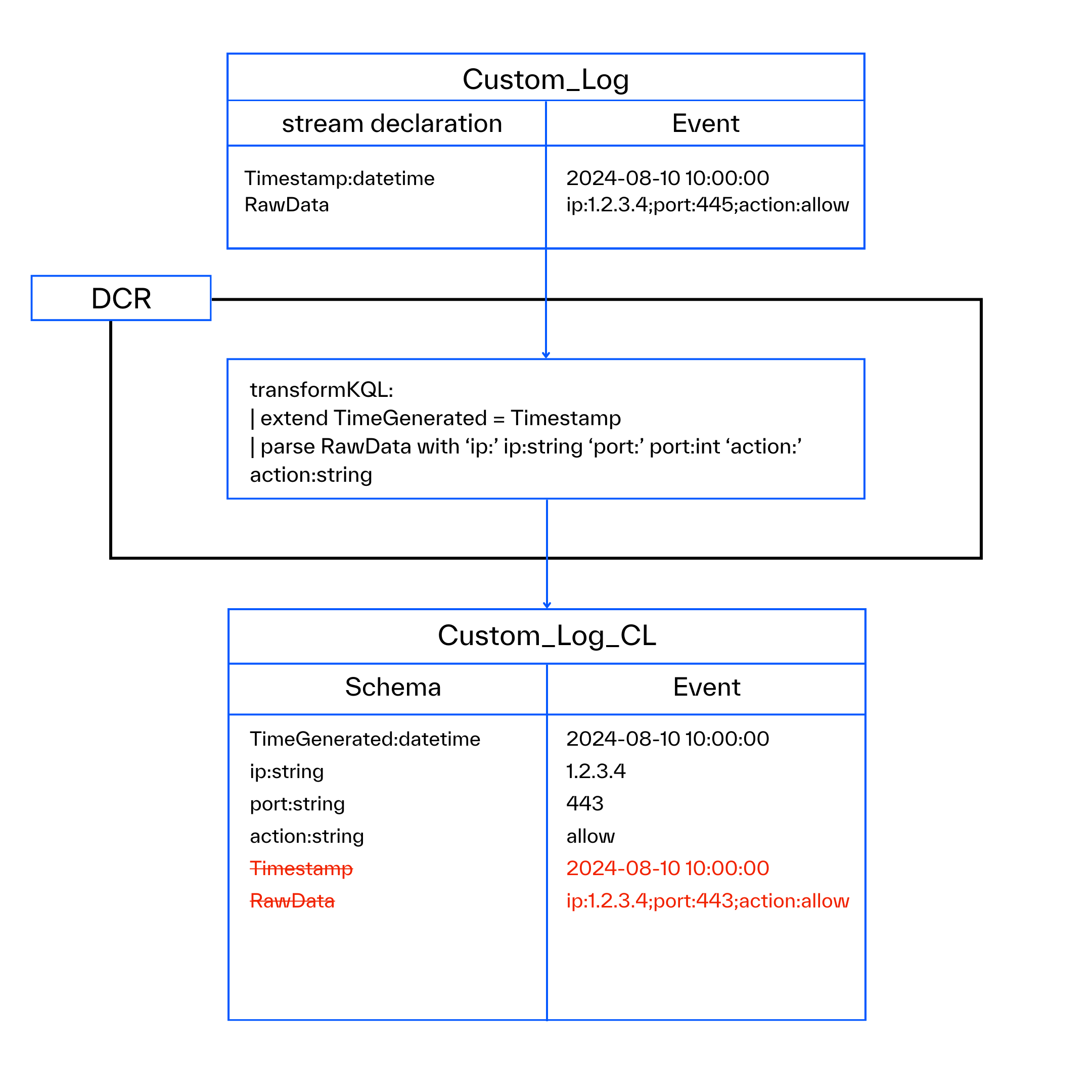
When you create a DCR-based Custom table, Azure requires you to upload a JSON-formatted sample file to determine the schema. Upon doing this, Azure creates a table with the specified schema and also creates (or updates) a DCR containing the same schema (referred to as streamDeclaration in the DCR).
This setup implies that, by default, the schema of the ingested data (streamDeclaration) and the schema of the table are identical. However, after this initial setup, you have the flexibility to modify the schema of either the table or the input data (streamDeclaration), and these changes will not be reflected in the other location. Additionally, you can create or remove fields using an ingestion-time transformation within the DCR.
Always verify the streamDeclaration of the DCR, apply any ingestion-time transformations if applicable, and compare the output schema with the schema of the destination table to identify phantom fields.
Common Issues and Solutions:
- Timestamp Field – A common issue is that the streamDeclaration contains a timestamp field with a generic name like ‘Timestamp’, while in Sentinel, the required field is named ‘TimeGenerated’. If you do not rename the existing field and instead create a new one, it often results in a duplicated field. This scenario involves only a duplicated timestamp, resulting in only a small amount of data being affected.
- RawData – When handling custom file-based logs, the content typically ends up in the RawData field. To enhance usability, it is recommended to extract values from this field into distinct fields. Be cautious to remove the RawData field after parsing to avoid storing the same data twice—once in the RawData field and once in the newly extracted custom fields.
- Unwanted Fields – To eliminate a field, it is not enough to simply remove it from the automatically generated table schema. You must also drop the field using an ingestion-time transformation or modify the input streamDeclaration.
Here is a diagram of the first two common issues:
3. Temporary Field Creation in Ingestion-time Transformation
Individuals often create temporary fields within their ingestion-time transformation in the DCR. These fields are typically utilized for:
- Filtering purposes
- Assisting in further calculations
However, they may inadvertently remain after their initial use. If these fields are not included in the table schema, this configuration can lead to the presence of phantom fields.
To avoid this issue, always process the input schema (the default table schema or the streamDeclaration) through the applicable ingestion-time transformation and compare the resulting schema with the table schema to identify any phantom fields.
Microsoft’s Approach
It is also important to see how Microsoft deals with this behavior within Microsoft Sentinel. Currently, the platform incurs ingestion costs for phantom fields, despite their inaccessibility.*
*Anyone can confirm this by pushing the same data to a Sentinel instance daily and adding more “phantom fields” each day (through ingestion-time transformations without updating the table schema). You will see that the Cost Management page shows you’re paying more and more, even though you’re not actually getting access to more data.
The majority of code provided by Microsoft effectively avoids phantom field creation. Their ingestion-time transformations frequently employ the ‘project-rename’ operator instead of ‘extend’, and the parsed ‘RawData’ is routinely dropped within the Data Collection Rules (DCRs).
However, instances of phantom field generation have been observed. A notable example is the Microsoft-recommended ingestion-time transformation for JuniperIDP logs, where temporary fields (third scenario from above) are not explicitly dropped. This leads to the creation of phantom fields.
For brevity, I have omitted some of the extractions, but the overall structure of the ingestion-time transformation is as follows:
source
| parse RawData with tmp_time ” ” host_s ” ” ident_s ” ” tmp_pid ” ” msgid_s ” ” extradata
| extend dvc_os_s = extract(“\\[(junos\\S+)”, 1, extradata)
| extend event_end_time_s = extract(“.*epoch-time=\”(\\S+)\””, 1, extradata)
//Omitted extract commands
| extend msg_s = extract(“.*message=\”(\\S+)\””, 1, extradata)
| project-away RawData
The ingestion-time transformation extracts various information into separate fields like: tmp_time, host_s, ident_s, tmp_pid, msgid_s, and extradata. Additionally, it extracts numerous values from the ‘extradata’ field into individual fields. This ‘extradata’ field serves as a temporary holding area during the extraction process.
While the ‘RawData’ field is subsequently dropped, the ‘extradata’ field remains. Since the values from ‘extradata’ are already extracted into individual fields, this creates duplicate data. Furthermore, if the ‘extradata ‘field is not defined in the destination table schema, it becomes an inaccessible phantom field.
Analysis of the legacy code reveals that the ‘extradata’ field was intended to be removed. However, this removal appears to have been forgotten during the migration from the OMS parser to the DCR.
Currently, none of the built-in health monitoring options or diagnostic settings provide you with information about this happening. Thus, at BlueVoyant we created our own tools to detect this.*
*We’ve been in contact with Microsoft through various channels about this issue, and we still have open tickets with them. They may have more information to share soon.
Recommendations
When forwarding logs to a new table or implementing a new transformation, it is crucial to verify both the output schema and the schema of the target table.
At BlueVoyant, we have automations to oversee this process, ensuring that we maintain a cost-effective Sentinel instance for our clients. We have encountered this issue in numerous environments. Based on our findings, here are some recommended steps:
- Always utilize project or project-keep as a final step to guarantee that you retain only the fields you need in the results. This step will also aid the future review of your DCRs.
- Instead of employing the format ‘| extend FieldA = FieldB,’ opt for ‘| project-rename FieldA = FieldB’ to prevent duplicate fields.
- Continuously monitor your environment to ensure that no changes lead to the creation of phantom fields.
Feel free to contact us if you require assistance in addressing this issue within your Sentinel environment.